Original Link: https://www.anandtech.com/show/6976/amds-jaguar-architecture-the-cpu-powering-xbox-one-playstation-4-kabini-temash
AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM EST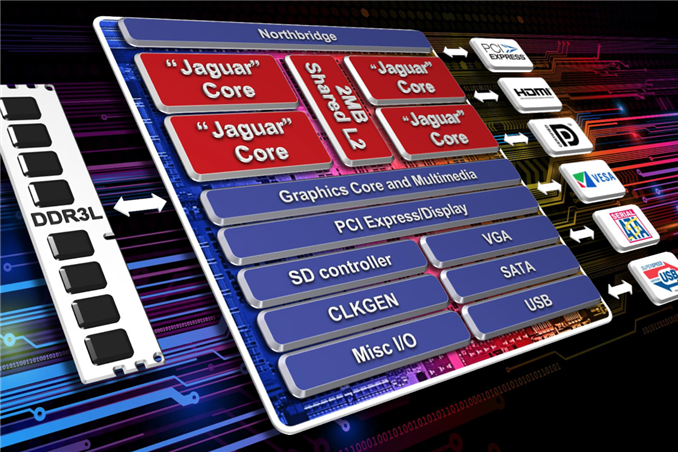
Microprocessor architectures these days are largely limited, and thus defined, by power consumption. When it comes to designing an architecture around a power envelope the rule of thumb is any given microprocessor architecture can scale to target an order of magnitude of TDPs. For example, Intel’s Core architectures (Sandy/Ivy Bridge) effectively target the 13W - 130W range. They can surely be used in parts that consume less or more power, but at those extremes it’s more efficient to build another microarchitecture to target those TDPs instead.
Both AMD and Intel feel similarly about this order of magnitude rule, and thus both have two independent microprocessor architectures that they leverage to build chips for the computing continuum. From Intel we have Atom for low power, and Core for high performance. In 2010 AMD gave us Bobcat for its low power roadmap, and Bulldozer for high performance.
Both the Bobcat and Bulldozer lines would see annual updates. In 2011 we saw Bobcat used in Ontario and Zacate SoCs, as a part of the Brazos platform. Last year AMD announced Brazos 2.0, using slightly updated versions of those very same Bobcat based SoCs. Today AMD officially launches Kabini and Temash, APUs based on the first major architectural update to Bobcat: the Jaguar core.






Jaguar: Improved 2-wide Out-of-Order
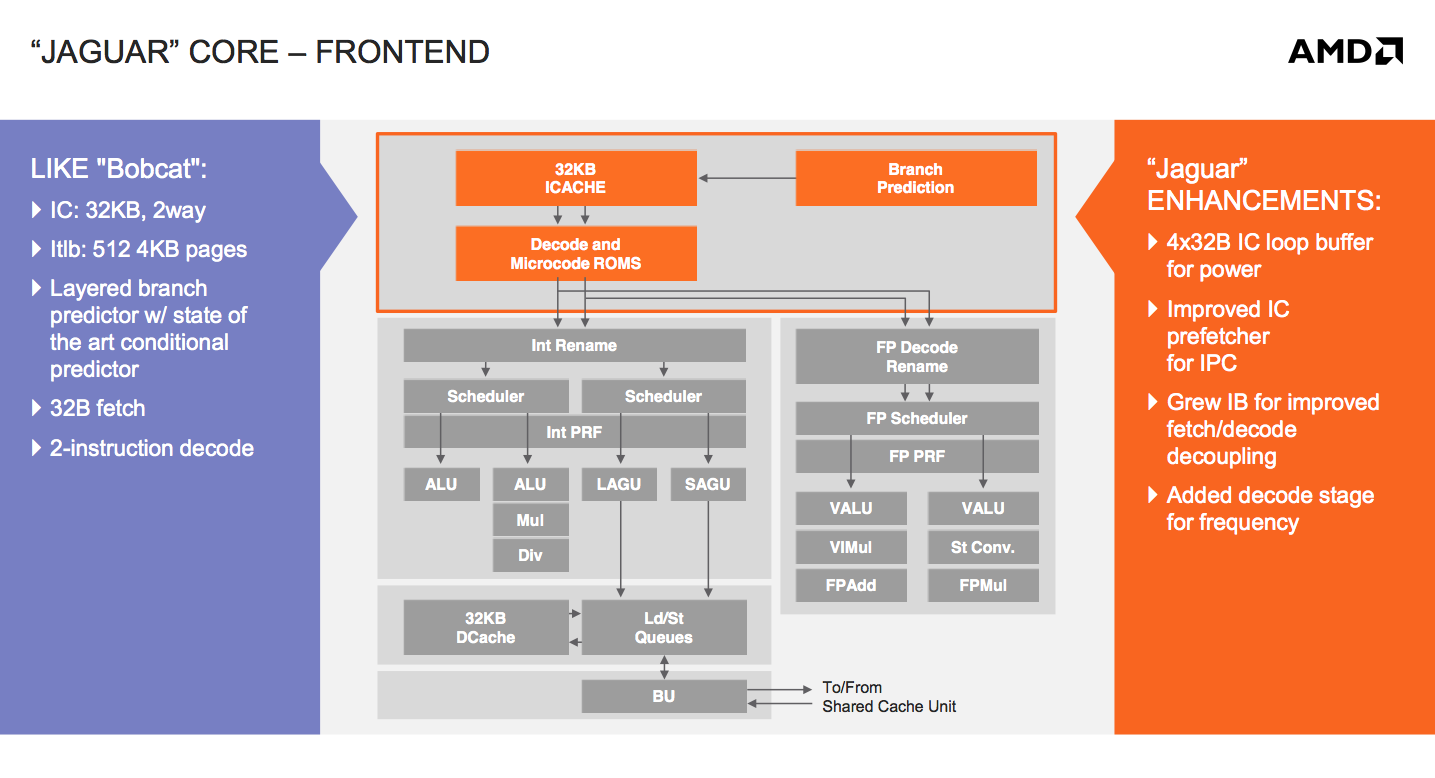
At the core-level, Jaguar still looks a lot like Bobcat. The same dual-issue, out-of-order architecture that AMD introduced in 2010 remains intact with Jaguar. The same L1 cache, front end and execution blocks are all still here. Given the ARM transition from a dual-issue, out-of-order core with Cortex A9 to a three-issue, OoO design with the Cortex A15, I expected something similar from AMD. Despite moving to a smaller manufacturing process (28nm), AMD was very focused on increasing performance within the same TDP or lower with Jaguar. The driving motivator? While Bobcat ended up in netbooks, nettops and other low cost, but thick machines, Jaguar needed to go into even thinner form factors: tablets. AMD still has no intentions of getting into the smartphone SoC space, but the Windows 8 (and Android?) tablet market is fair game. Cellular connectivity isn’t a requirement there, particularly at the lower price points, and AMD can easily be a second source alternative to Intel Atom based designs.
The average number of instructions executed per clock (IPC) is still below 1 for most client workloads. There’s a certain amount of burst traffic to be expected but given the types of dependencies you see in most use cases, AMD felt the gain from making the machine wider wasn’t worth the power tradeoff. There’s also the danger of making the cat-cores too powerful. While just making them 3-issue to begin with wouldn’t dramatically close the gap between the cat-cores and the Bulldozer family, there’s still a desire for there to be clear separation between the two microarchitectures.
The move to a three-issue design would certainly increase performance, but AMD’s tablet ambitions and power sensitivity meant it would save that transition for another day. I should point out that ARM is increasingly looking like the odd-man-out here, with both Jaguar and Intel’s Silvermont retaining the dual-issue design of their predecessors. Part of this has to do with the fact that while AMD and Intel are very focused on driving power down, ARM has aspirations of moving up in the performance/power chain.
The width of the front end is only one lever AMD could have used to increase performance. While it was a pretty big lever that AMD chose not to pull, there are other smaller levers that were exercised in Jaguar.
There’s now a 4 x 32-byte loop buffer for the instruction cache. Whenever a loop is detected, instead of fetching instructions executed in the loop from the L1 I-cache over and over again, they’re serviced from this small loop buffer. If this sounds like a trace cache or decoded micro-op cache, don’t get too excited, Jaguar’s loop buffer is neither of these things. There are no pipeline savings or powered down fetch/decode units. The only benefit to the new loop buffer is the instruction cache doesn’t have to be fired up during every iteration of a buffered loop. In other words, this is a very specific play to reduce power consumption - not to improve performance.
All microprocessors see tons of simulation work before they’re ever brought to market. Even once a design is done, additional profiling is used to identify bottlenecks, which are then prioritized for addressing in future designs. All bottleneck removal has to be vetted against power, cost and schedule constraints. Given an infinite budget across all vectors you could eliminate all bottlenecks, but you’d likely take an infinite amount of time to complete the design. Taking all of those realities into account usually means making tradeoffs, even when improving a design.
We saw the first example of a clear tradeoff when AMD stuck with a 2-issue front end for Jaguar. Not including a decoded micro-op cache and opting for a simpler loop buffer instead is an example of another. AMD likely noticed a lot of power being wasted during loops, and the addition of a loop buffer was probably the best balance of complexity, power savings and cost.
AMD also improved the instruction cache prefetcher, not because of an over abundance of bandwidth but by revisiting the Bobcat design and spending some more time on the implementation in Jaguar. The IC prefetcher improvements are simply AMD doing things better in Jaguar, not being under the same pressure to introduce a brand new architecture as was the case with Bobcat.
The instruction buffer between the instruction cache and decoders grew in size with Jaguar, a sort of half step towards the more heavily decoupled fetch/decode stages in Bulldozer.
Jaguar adds support for new instructions (SSE4.1/4.2, AES, CLMUL, MOVBE, AVX, F16C, BMI1) as well as 40-bit physical addressing.
The final change to the front of Jaguar was the addition of another decode stage, purely for frequency gains. It turns out that in Bobcat the decoder was one of the critical paths limiting maximum frequency. Adding another decode stage simply gave AMD enough wiggle room to hit their frequency targets for Jaguar at 28nm.
Integer & FP Execution
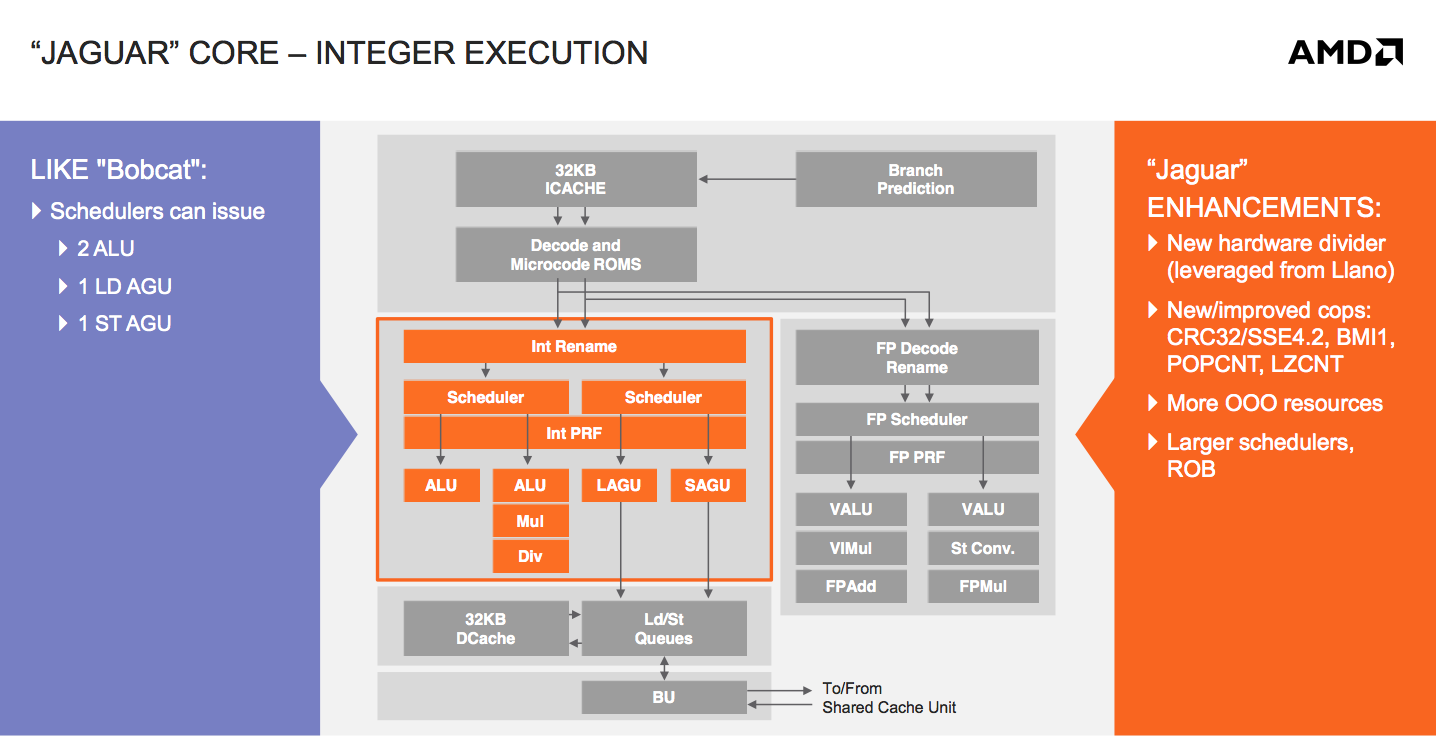
On the integer execution side, units and pipelines look largely unchanged from Bobcat. The big performance addition here is the use of Llano’s hardware divider. Bobcat had a microcoded integer divider capable of one bit per cycle, while Jaguar moves to a 2-bits-per-cycle divider. The hardware is all clock gated, so when it’s not in use there’s no power penalty.
The schedulers and re-order buffer are incrementally bigger in Jaguar. Some scheduling changes and other out of order resource increases are at work here as well.
Integer performance wasn’t a huge problem with Bobcat to begin with, but floating point performance was a different issue entirely. In our original Brazos review we found that heavily threaded FP workloads were barely faster on Bobcat than they were on Atom. A big part of that had to do with Atom’s support for Hyper Threading. AMD addressed both issues by beefing up FP execution and doubling up the maximum number of CPU cores with Jaguar (more on this later).
Bobcat’s FP execution units were 64-bits wide. Any 128-bit FP operations had to be chunked up and worked on in stages. In Jaguar, AMD moved all of its units to 128-bits wide. AVX operations complete as 2 x 128-bit operations, while all other 128-bit operations can execute without multiple passes through the pipeline. The increase in vector width is responsible for the gains in FP performance.
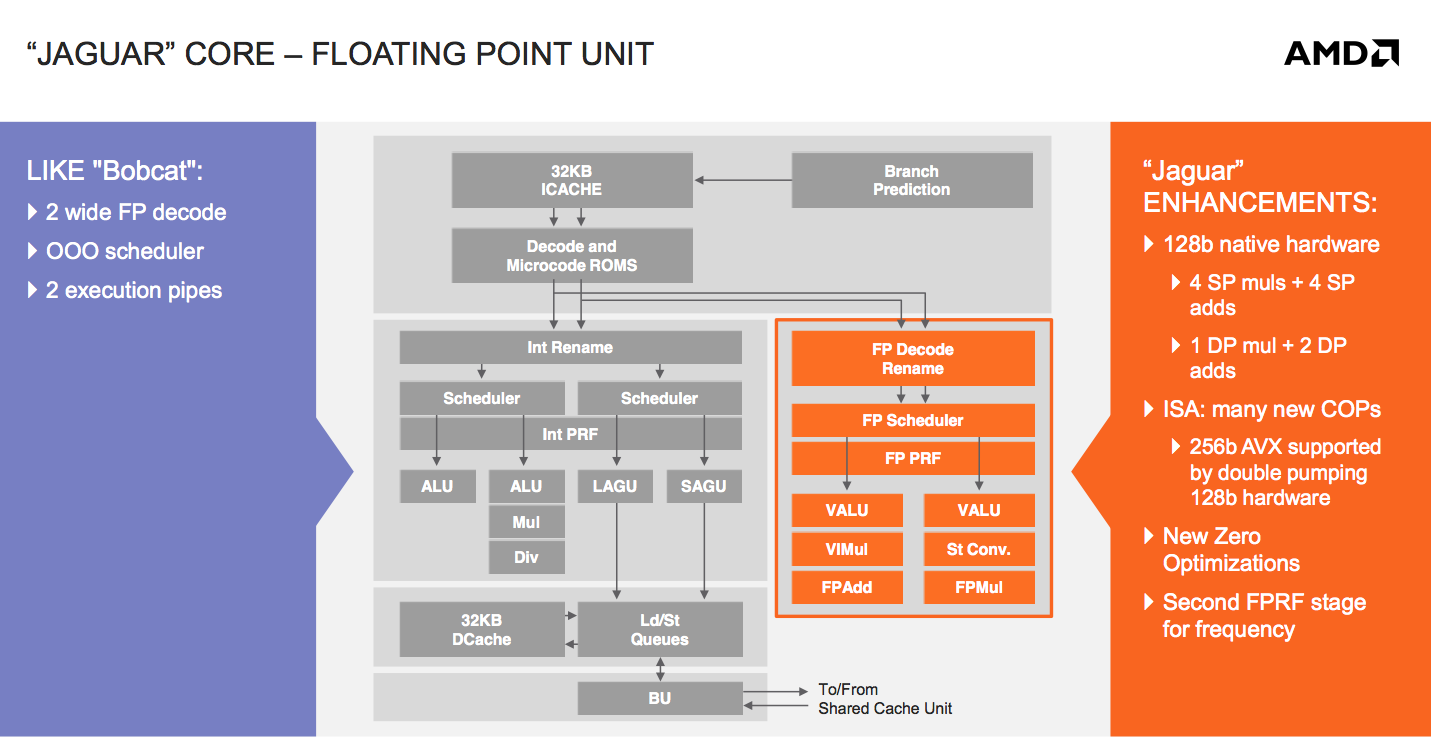
The move to 128-bit vectors in the FPU forced AMD to add another pipeline stage here as well. The increase in FPU size meant that some signals needed a little extra time to get from one location to the next, hence the extra stage.
Load/Store
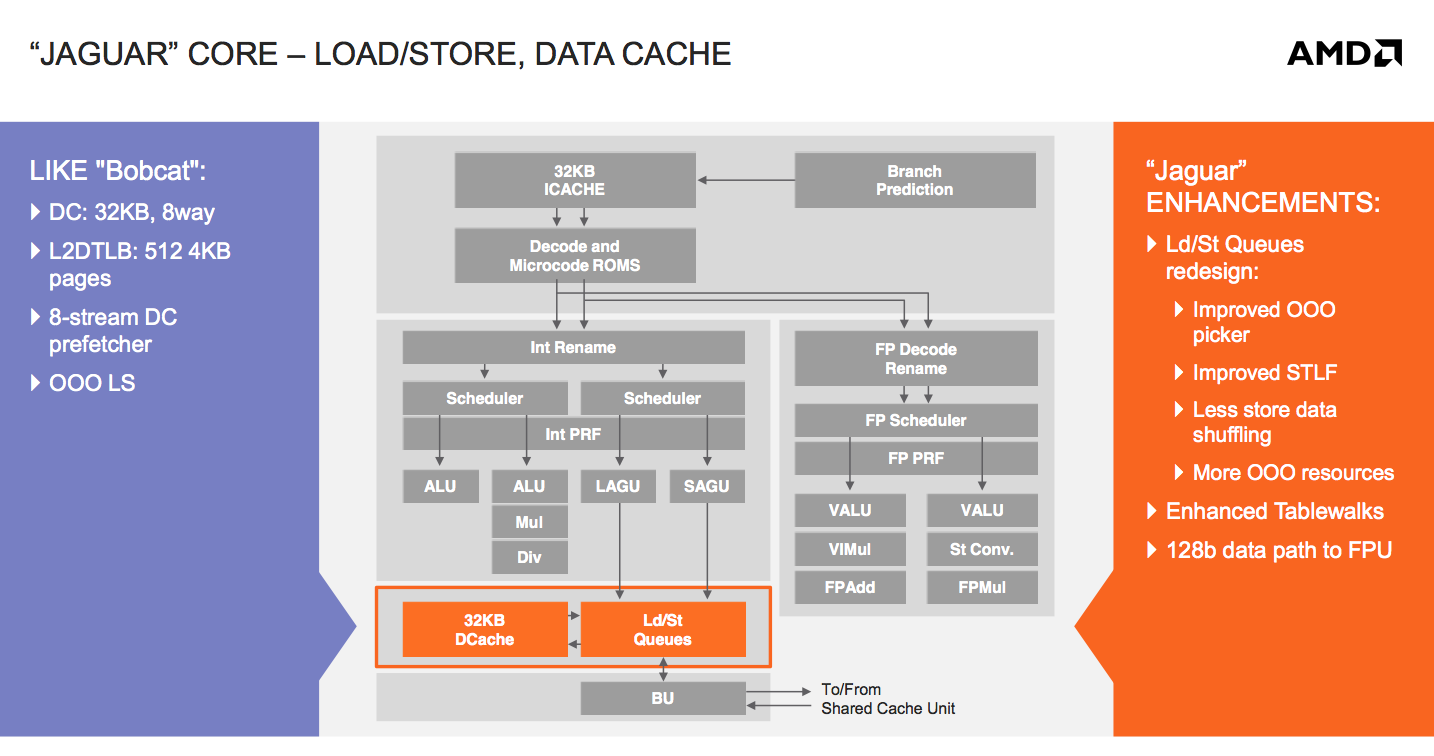
The out-of-order load/store unit in Bobcat was the first one AMD had ever done (Bobcat beat Bulldozer to market, so it gets the claim to fame there). As such there was a good amount of room for improvement, which AMD capitalized on in Jaguar. The second gen OoO load/store unit is responsible for a good amount of the ~15% gains in IPC that AMD promises with Jaguar.

Compute Unit
Bobcat was pretty simple from a multi-core standpoint. Each Bobcat core had its own private 512KB L2 cache, and all core-to-core communication happened via a bus interface on each of the cores. The cache hierarchy was exclusive, as has been the case with all of AMD’s previous architectures.
Jaguar changes everything. AMD defines a Jaguar compute unit as up to four cores with a single, large, shared L2 cache. The L2 cache can be up to 2MB in size and is 16-way set associative. The L2 cache is also inclusive, a first in AMD’s history. In the past AMD always implemented exclusive caches as the inclusive duplicating of L1 data in L2 meant a smaller effective L2 cache. The larger shared L2 cache is responsible for up to another 5-7% increase in IPC over Bobcat (totaling ~22%).
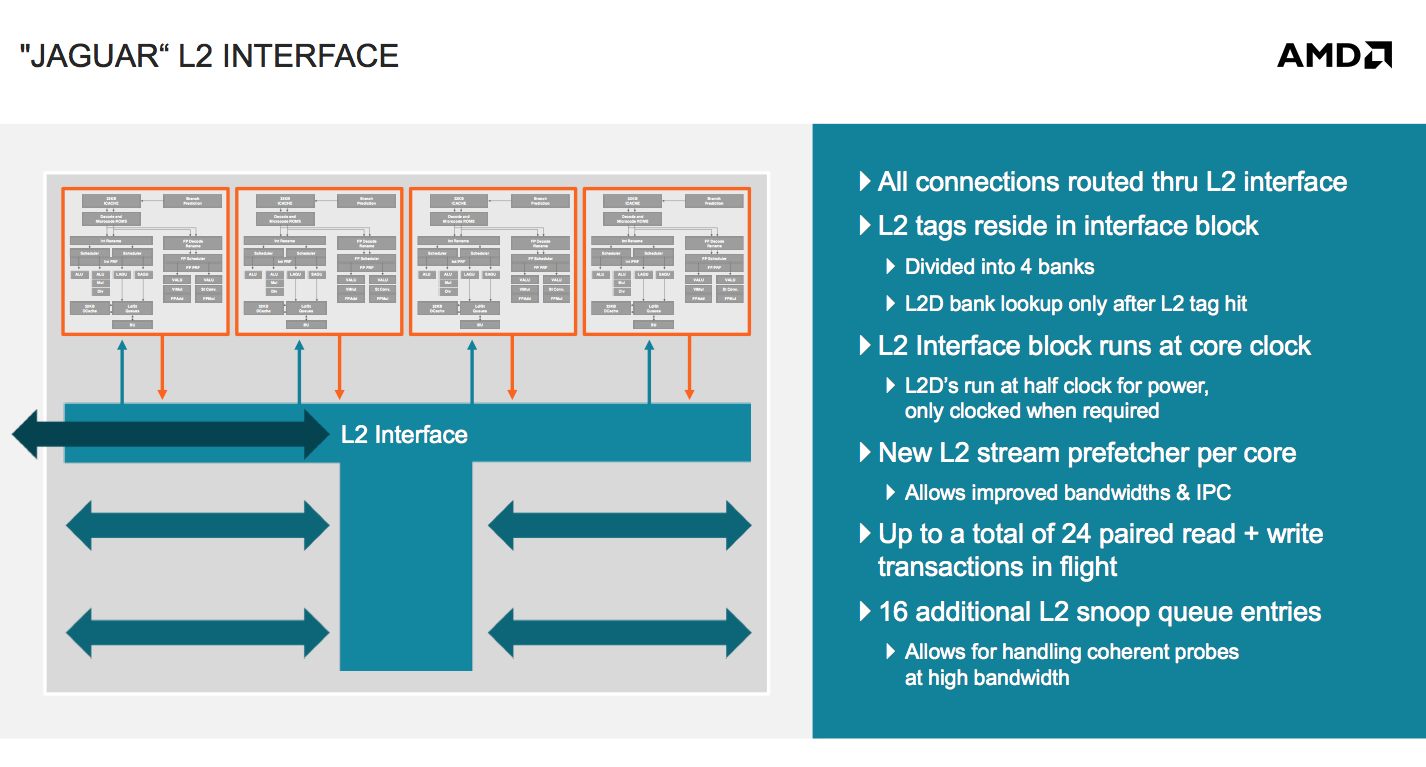
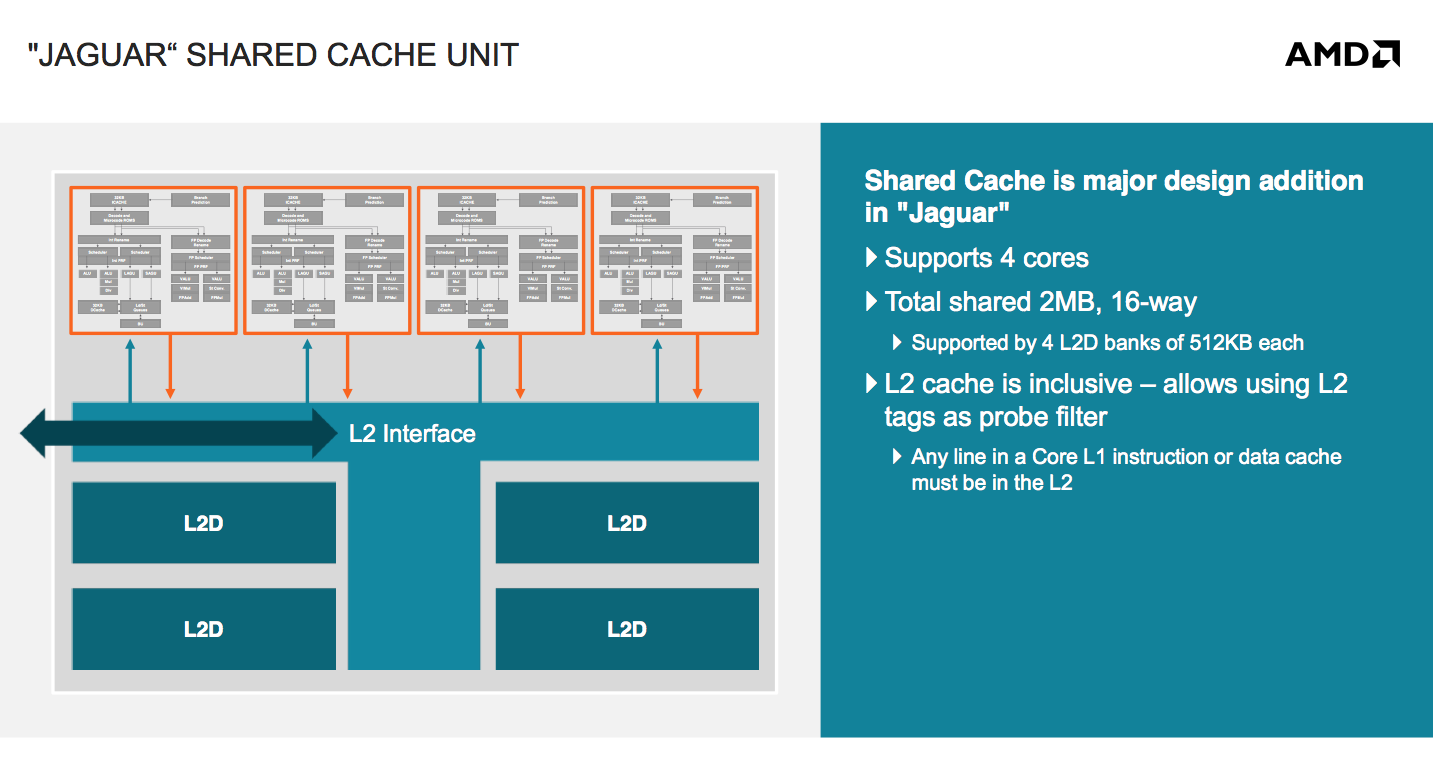
AMD’s new cache architecture and lower latency core-to-core communication within a Jaguar compute unit means an even greater performance advantage over Bobcat in multithreaded workloads:
| Multithreaded Performance Comparison | ||||||||||||||||
| # of Cores | Cinebench 11.5 (Single Threaded) | Cinebench 11.5 (Multithreaded) | ||||||||||||||
| AMD A4-5000 (1.5GHz Jaguar x 4) | 4 | 0.39 | 1.5 | |||||||||||||
| AMD E-350 (1.6GHz Bobcat x 2) | 2 | 0.32 | 0.61 | |||||||||||||
| Advantage | 100% | 21.9% | 145.9% | |||||||||||||
The L1 caches remain unchanged at 32KB/32KB (I/D cache) per core.
Physical Layout and Synthesis
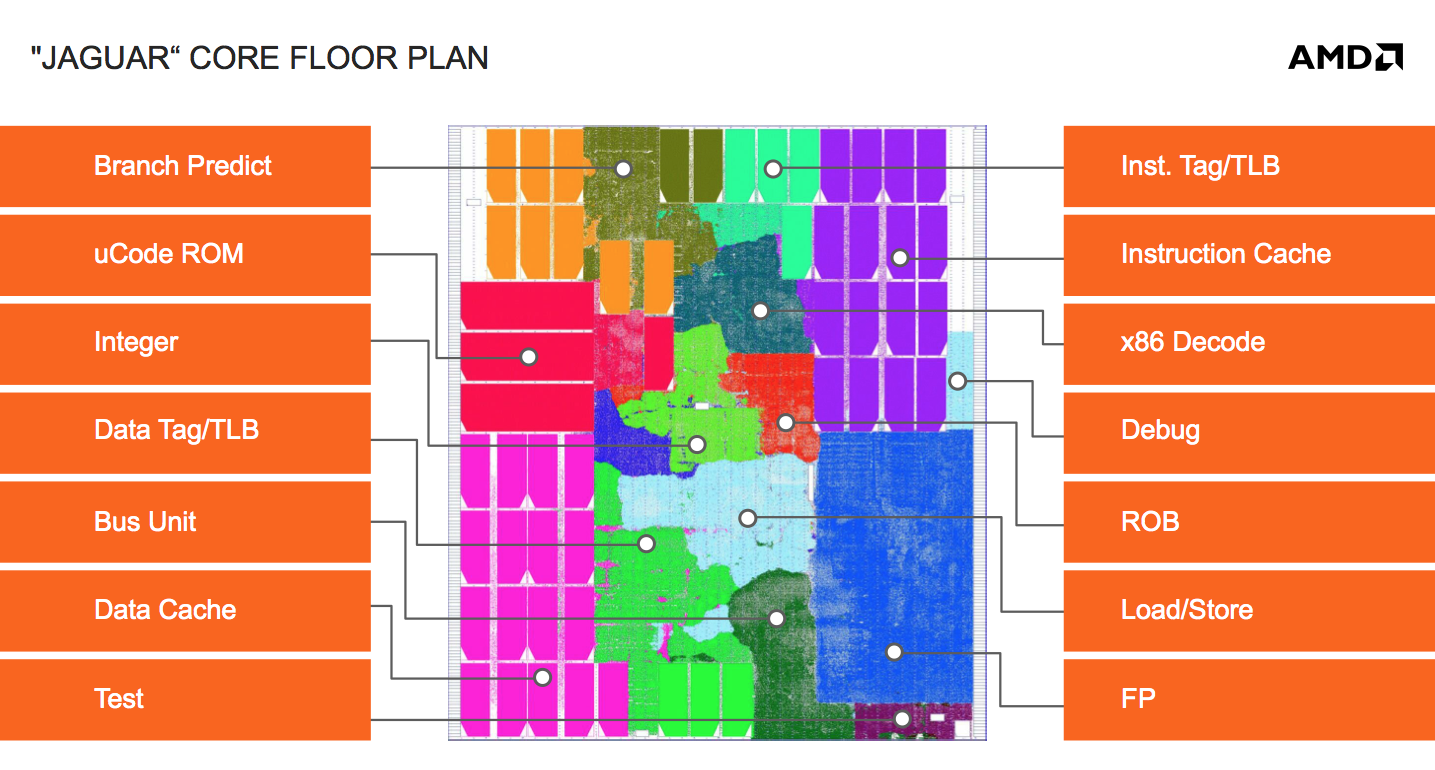
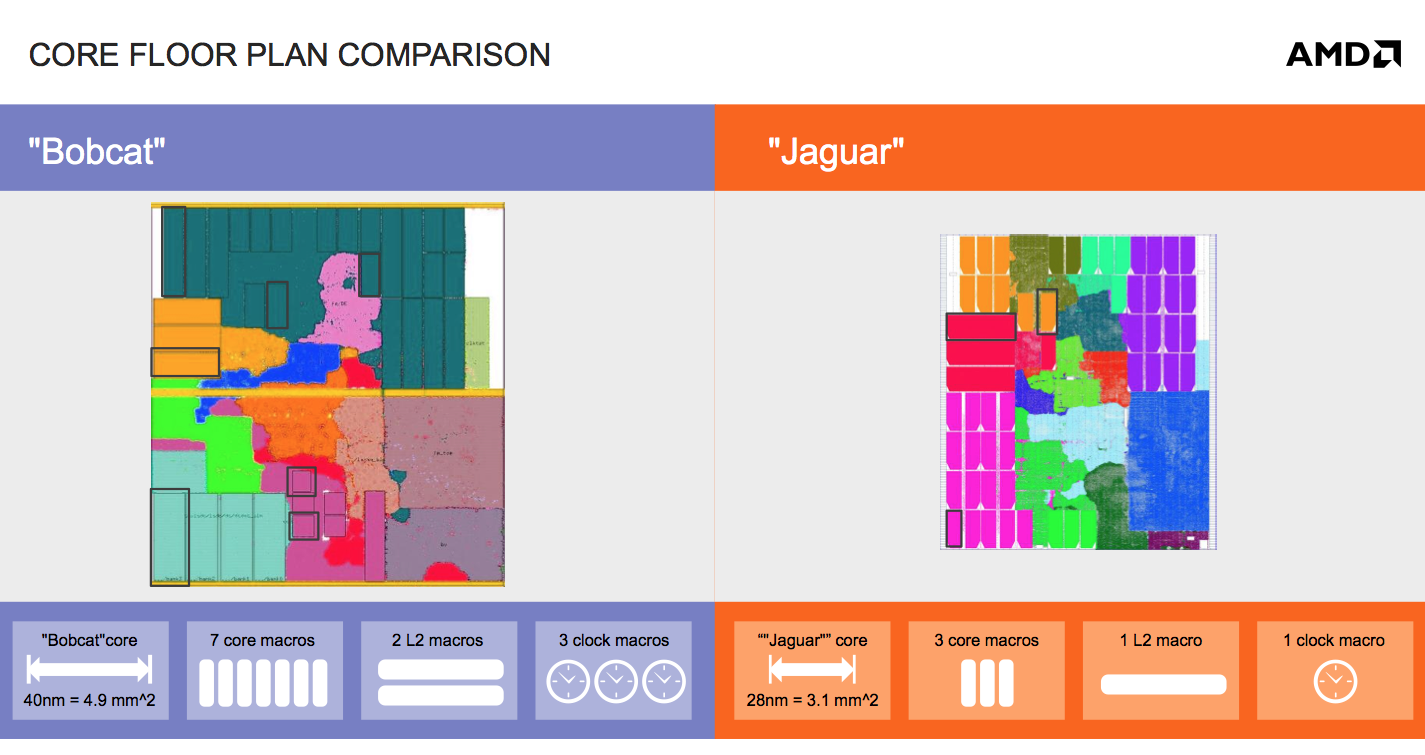
Bobcat was AMD’s first easily synthesized CPU core, it was a direct result of the ATI acquisition years before. With Jaguar, AMD made a conscious effort to further reduce the number of unique macros required by the design. The result was a great simplification, which helped AMD port Jaguar between foundries. There’s of course an area tradeoff when moving away from custom macros to more general designs but it was deemed worthwhile. Looking at the results, you really can’t argue. A single Jaguar core measures only 3.1mm^2 at 28nm compared to 4.9mm^2 for a 40nm Bobcat.
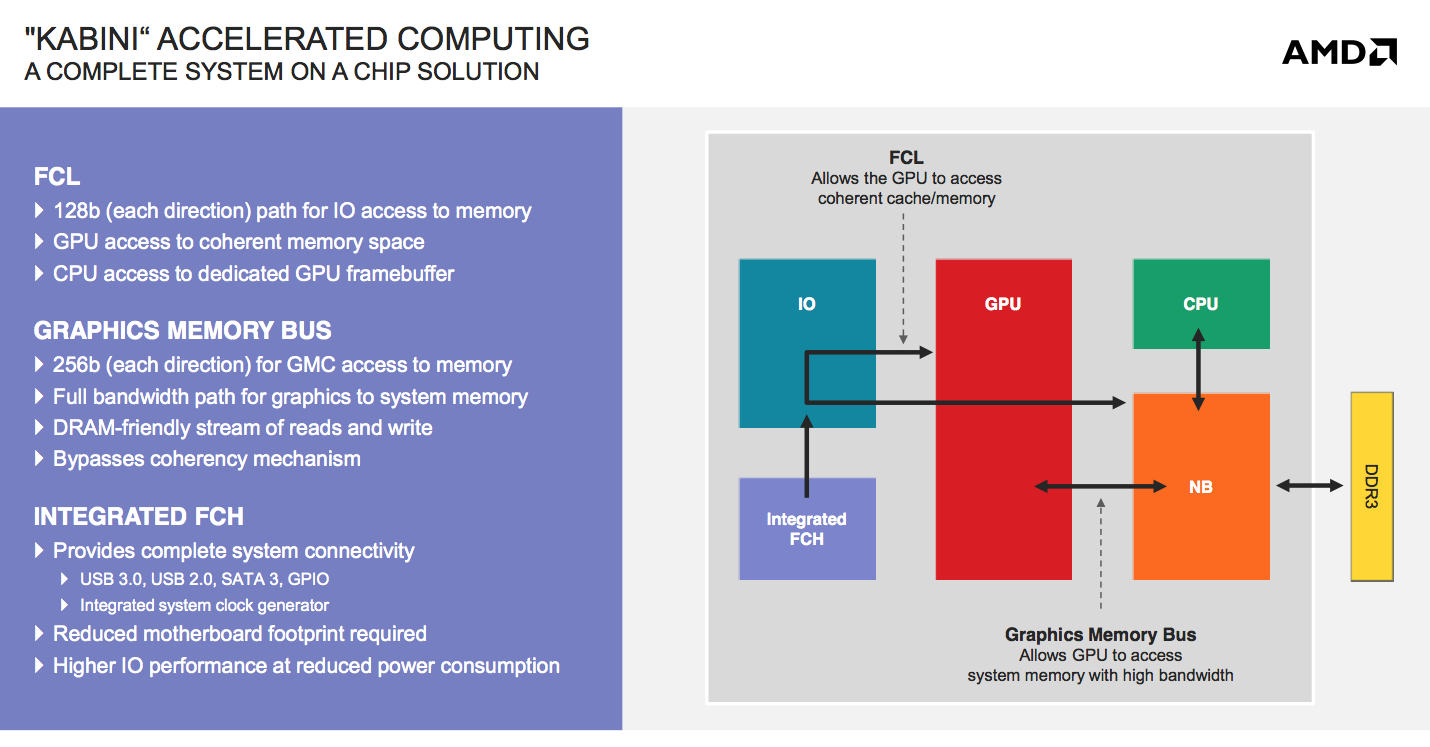
Kabini: Mainstream APU for Notebooks
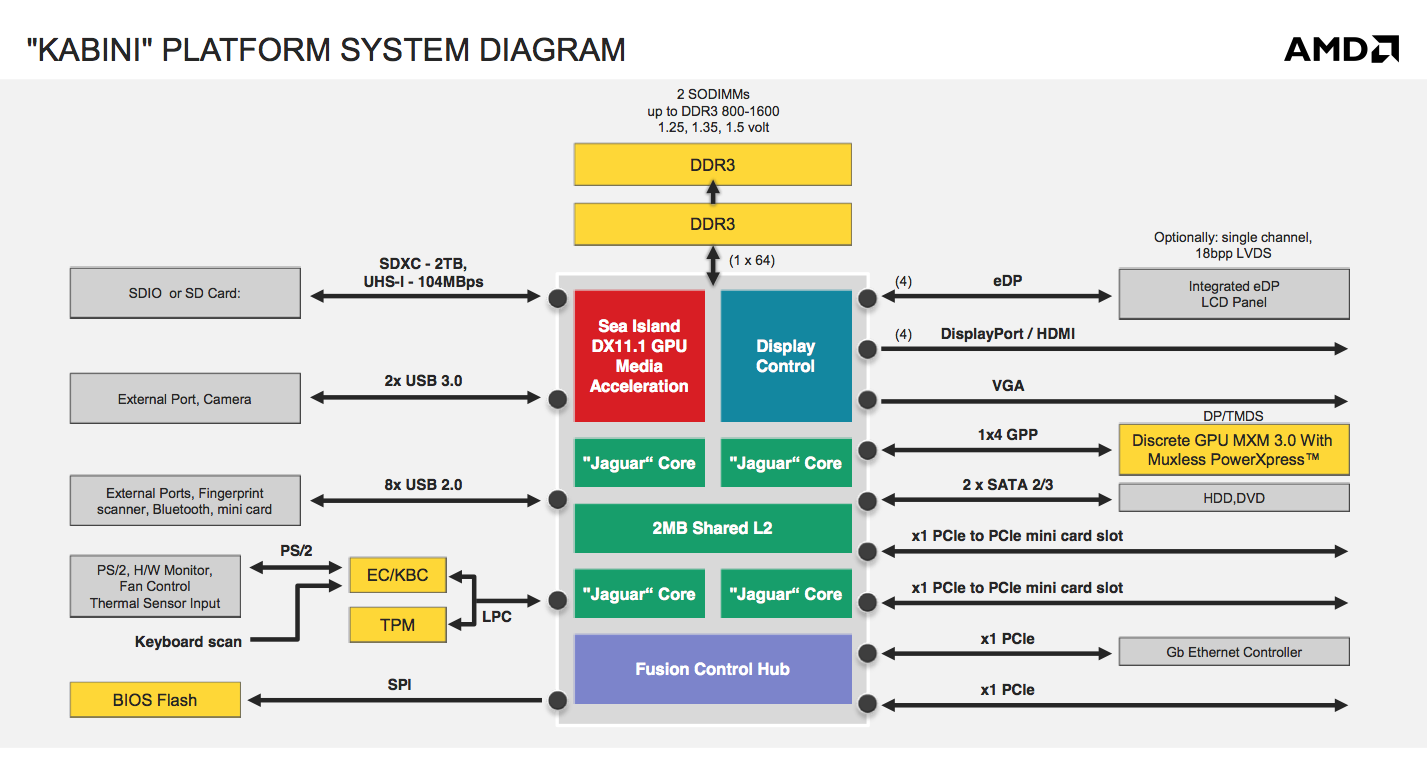
AMD will be building two APUs based on Jaguar: Kabini and Temash. Kabini is AMD’s mainstream APU, which you can expect to see in ultra-thin affordable notebooks. Note that both of these are full blown SoCs by conventional definitions - the IO hub is integrated into the monolithic die. Kabini ends up being the first quad-core x86 SoC if we go by that definition.
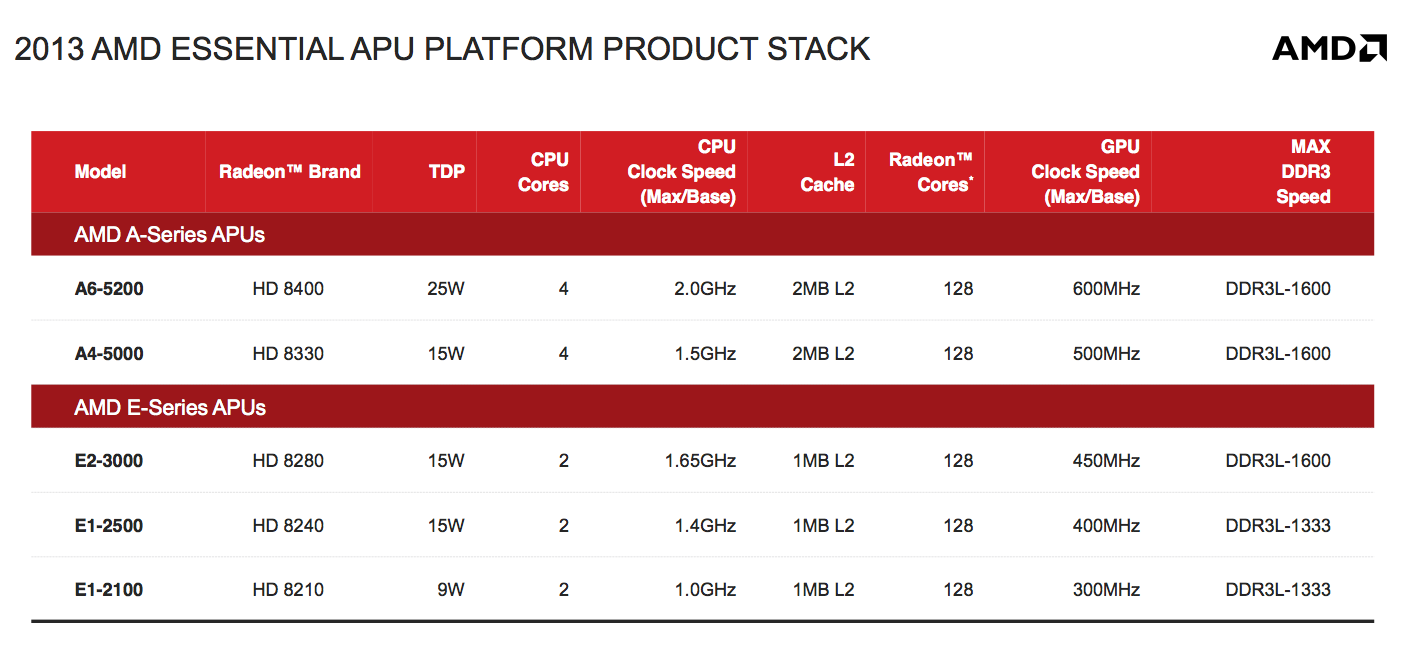
Kabini will carry A and E series branding, and will be available in a full quad-core version (A series) as well as dual-core (E series). The list of Kabini parts launching is below:
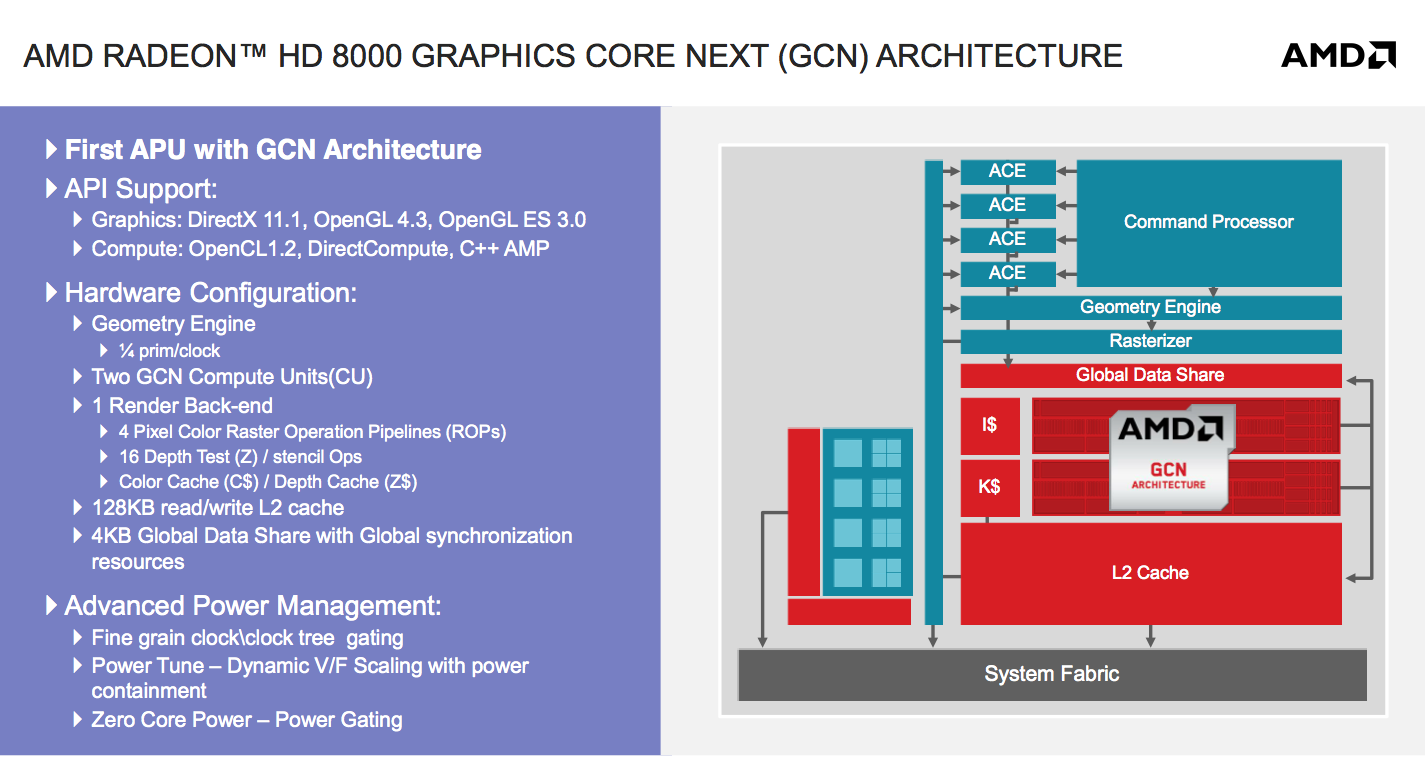
On the GPU side we have a 2 Compute Unit implementation of AMD’s Graphics Core Next architecture. The geometry engine has been culled a bit (1/4 primitive per clock) in order to make the transition into these smaller/low cost APUs. Double precision is supported at 1/16 rate, although adds and some muls will run at 1/8 the single precision rate.

Kabini features a single 64-bit DDR3 memory controller and ranges in TDPs from 9W to 25W. Although Jaguar supports dynamic frequency boosting (aka Turbo mode), the feature isn’t present/enabled on Kabini - all of the CPU clocks noted in the table above are the highest you’ll see regardless of core activity.
We have a separate review focusing on the performance of AMD’s A4-5000 Kabini APU live today as well.
Temash: Entry Level APU for Tablets
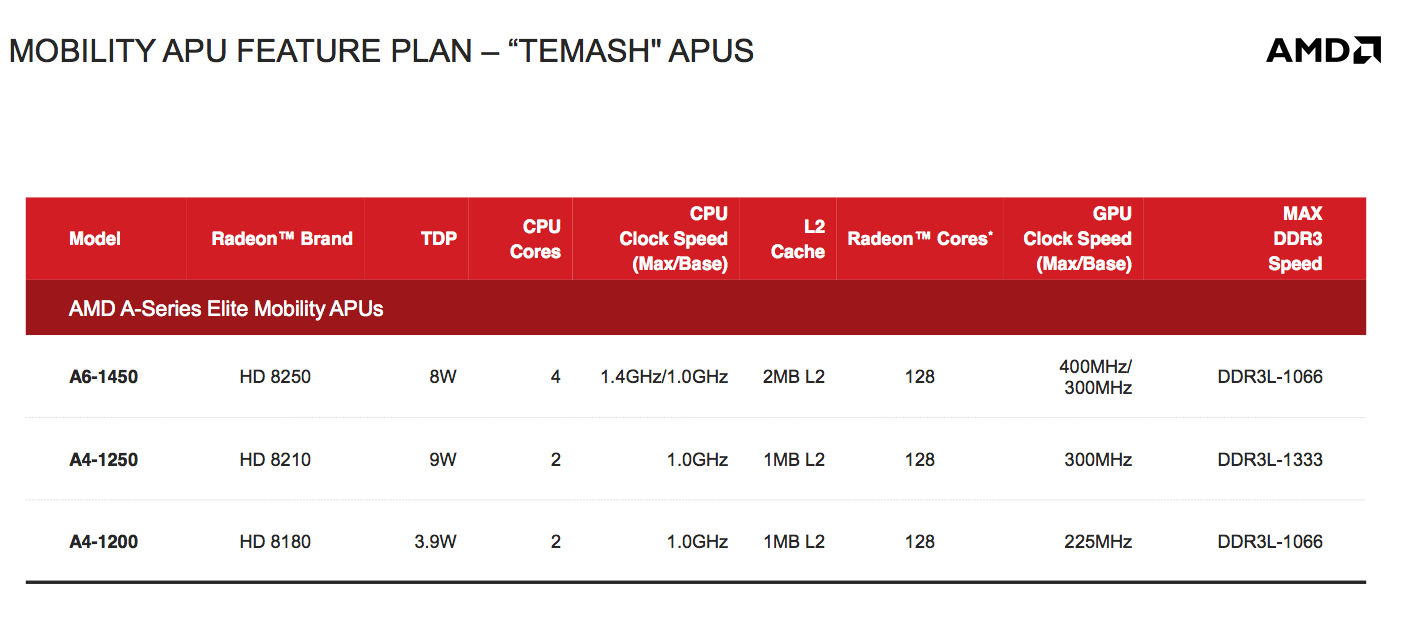
While Kabini will go into more traditional notebook designs, Temash will head down into the tablet space. The Temash TDPs range from 3.9W all the way up to 9W. Of the three Temash parts launching today, two are dual-core designs with the highest end A6-1450 boasting 4 cores as well as support for turbo core. The A6-1450’s turbo core implementation also enables TDP sharing between the CPU and GPU cores (idle CPUs can be power gated and their thermal budget given to the GPU, and vice versa).
The A4-1200 is quite interesting as it carries a sub-4W TDP, low enough to make it into an iPad-like form factor. It’s also important to note that AMD doesn’t actually reduce the number of GPU cores in any of the Temash designs, it just scales down clock speed.
Xbox One & PlayStation 4
In both our Xbox One and PS4 articles I referred to the SoCs as using two Jaguar compute units - now you can understand why. Both designs incorporate two quad-core Jaguar modules, each with their own shared 2MB L2 cache. Communication between the modules isn’t ideal, so we’ll likely see both consoles prefer that related tasks run on the same module.
Looking at Kabini, we have a good idea of the dynamic range for Jaguar on TSMC’s 28nm process: 1GHz - 2GHz. Right around 1.6GHz seems to be the sweet spot, as going to 2GHz requires a 66% increase in TDP.
The major change between AMD’s Temash/Kabini Jaguar implementations as what’s done in the consoles is really all of the unified memory addressing work and any coherency that’s supported on the platforms. Memory buses are obviously very different as well, but the CPU cores themselves are pretty much identical to what we’ve outlined here.
Final Words
Bobcat was a turning point for AMD. The easily synthesized, low cost CPU design was found in the nearly 50 million Brazos systems AMD sold since its introduction. Jaguar improves upon Bobcat in a major way. The move to 28nm helps drive power even lower, which will finally get AMD into tablet designs with Temash. Despite being lower power, Jaguar also manages to increase performance appreciably over Bobcat. AMD claims up to a 22% increase in IPC compared to Bobcat. Combine the IPC gains with a more multi-core friendly design and Jaguar based APUs should be appreciably faster than their predecessors.

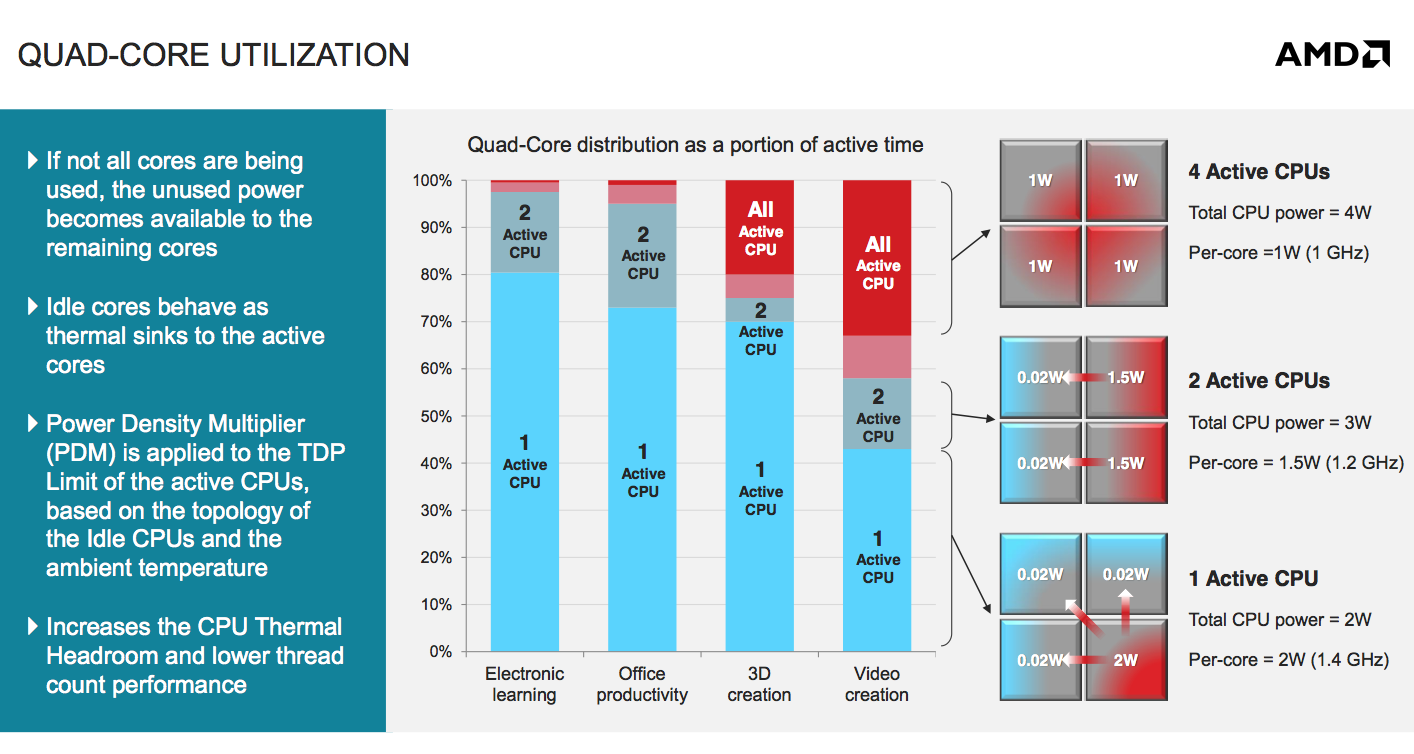
Quite possibly one of the only real weaknesses with Jaguar is the lack of aggressive turbo modes in any of the shipping implementations of the design. It appears that the first implementations of Jaguar were under time constraints, leaving many features (including improved thermal monitoring/management and turbo boost) on the cutting room floor. Kabini and Temash seem ripe for a mid-cycle update enabling turbo across more parts, which could do wonders for single threaded performance.
The Jaguar power story actually looks very good, it's just hampered by traditional PC legacy. None of the launch APUs here support the low power IOs necessary to drive platform power down even further. AMD is getting very close though. Jaguar's core power is easily sub-2W for lightweight tablet tasks, the rest of the platform (excluding display) drives it up to 4 - 7W. AMD definitely has the right building blocks to go after truly low power tablets in a major way, should it have the resources and bandwidth to do so.
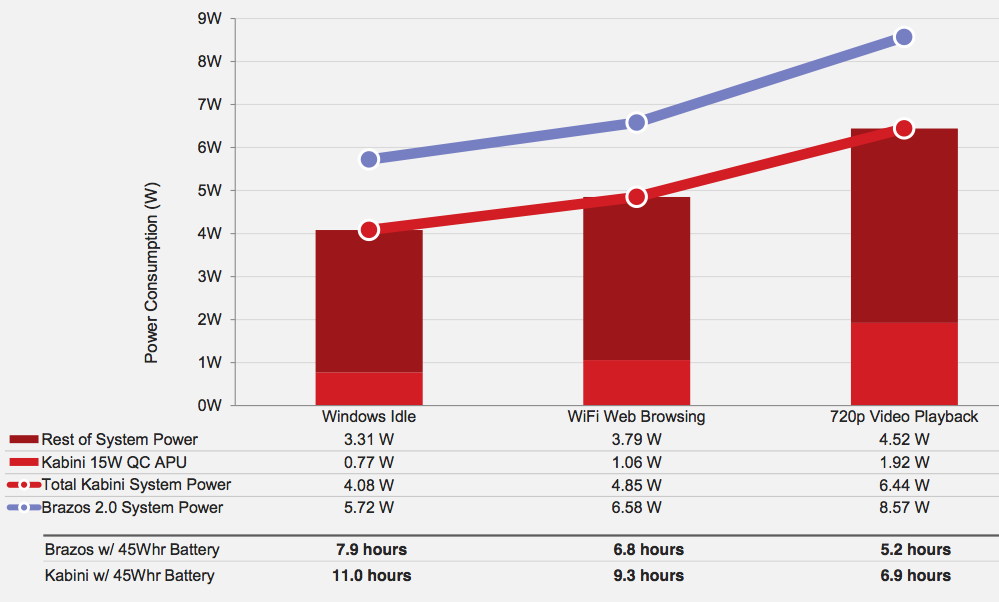
In its cost and power band, Jaguar is presently without competition. Intel’s current 32nm Saltwell Atom core is outdated, and nothing from ARM is quick enough. It’s no wonder that both Microsoft and Sony elected to use Jaguar as the base for their next-generation console SoCs, there simply isn’t a better option today. As Intel transitions to its 22nm Silvermont architecture however Jaguar will finally get some competition. For the next few months though, AMD will enjoy a position it hasn’t had in years: a CPU performance advantage.
I can’t stress enough how important it is that AMD continues to focus on driving the single threaded performance of its cat-line of cores. Second chances are rare in this business, but that’s exactly what AMD has been offered with the rise of good enough computing. Jaguar vs. Atom is the best CPU story AMD has had in years. Regular updates to the architecture coupled with solid execution are necessary to ensure that history doesn’t repeat itself in a new segment of AMD’s business.
Long term, I can’t help but wonder what Bobcat’s success will do to shape AMD’s future microarchitecture decisions. I’m not sure what Jim Keller’s SoC project is, but I’m wondering if the days of really big cores might be over. I don’t know that really small cores are the answer either, but perhaps something in between...






